Статьи
Авторы
НИОКР-проект SAREX: автоматизированный анализ отклонений между облаками точек, моделями и документацией

Максим Рогожкин

15/9/2025

В 2025-м Sarex реализовал НИОКР-проект по созданию автоматизированного инструмента для анализа отклонений между тремя основными типами данных: 3D-моделями, облаками точек, полученными с помощью лазерного сканирования, и графической документацией — проектной и исполнительной. В этой статье руководитель команды алгоритмов Sarex делится целями, техническими вызовами, методологией и результатами этого инновационного проекта.
Основной целью НИОКР было подтверждение возможности создания автоматизированной системы, способной выявлять несоответствия между различными типами данных, используемыми в строительных проектах. Мы стремились разработать алгоритм, который сравнивает:
Гипотеза состояла в том, чтобы выяснить — можно ли создать инструмент, который автоматически выявляет отклонения между этими наборами данных с высокой точностью.
Актуальность проекта вызвана, с одной стороны, подтвержденной высокой эффективностью технологии контроля отклонений с помощью лазерного сканирования, а с другой - барьерами в ее широком применении вследствие отсутствия BIM-моделей, соответствующих стадии РД (по которой выполняются строительно-монтажные работы). Соответственно, высока потребность в инструменте, который позволяет сравнить облако точек с 2D-документацией и подсветить несоответствия BIM-модели и рабочей документации.
Сравнение 2D-чертежей, 3D-моделей и облаков точек осложнялось их разной природой. 2D-чертежи описывают геометрию линиями, 3D-модели представляют объемные объекты с богатой семантикой, а облака точек — это сотни миллионов координат, где форма не задана явно из-за шумов, лазерных теней и пропусков.
Облака точек, достигающие объемов до 1.5 ТБ, создавали сложности из-за отсутствия четких контуров. Мы разработали метод аппроксимации, воссоздающий формы объектов, таких как стены или колонны, с помощью объемного сечения: 2D-контур вытягивался в 3D-объем, из которого вырезались соответствующие точки для точного расчета отклонений.
2D-документация добавляла вызовов, так как содержала неструктурированные элементы — аннотации, подчеркивания, нестандартные обозначения. Извлечение фактических измерений требовало тщательной обработки, чтобы обеспечить надежное сравнение с проектными данными.
Это потребовало оптимизации алгоритмов, чтобы сбалансировать вычислительные затраты и точность на стандартном оборудовании.
Для достижения цели наша команда структурировала решение на три основных компонента, каждый из которых решает ключевую задачу процесса анализа.
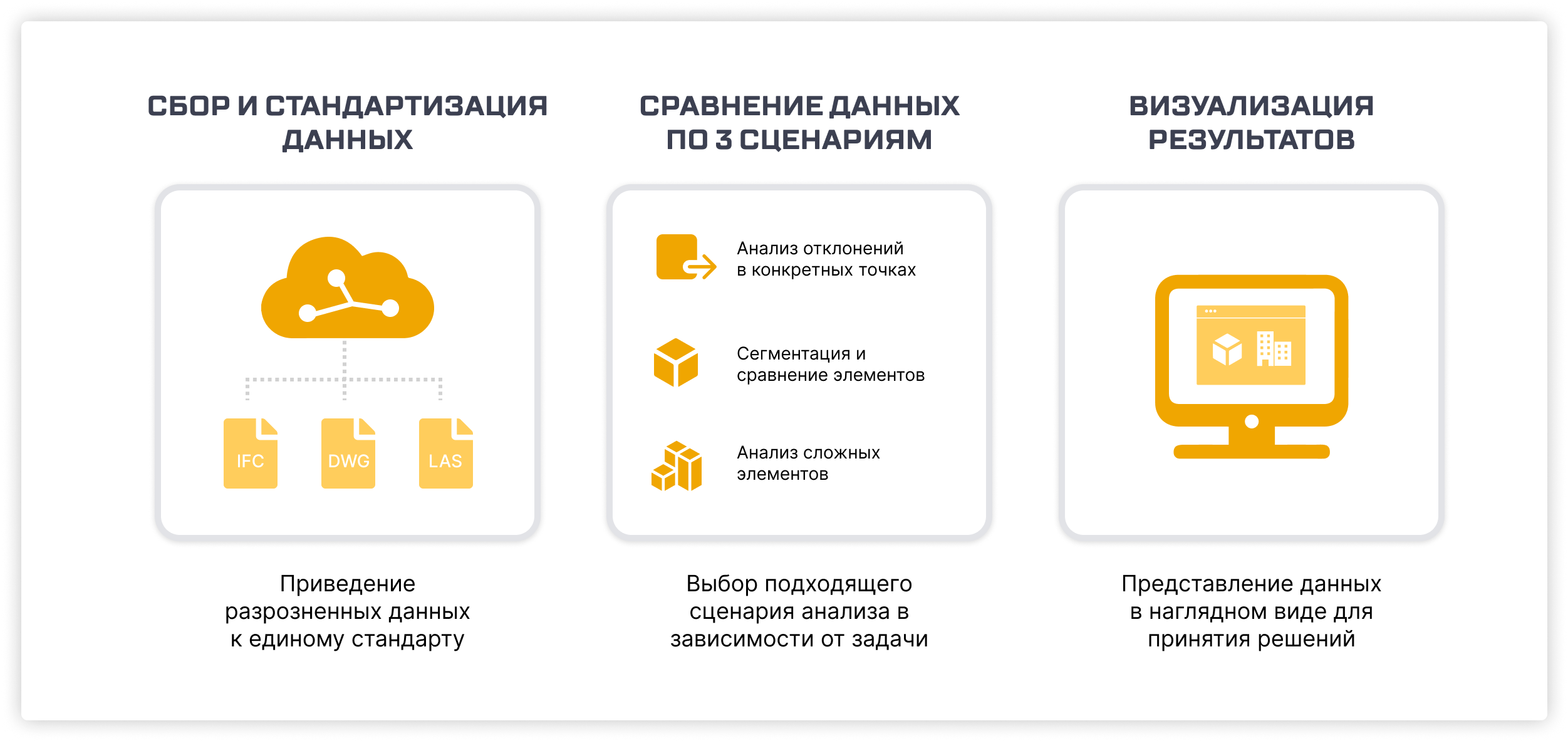
Первой задачей было приведение разнородных форматов данных к единому виду. Строительные проекты генерируют данные в различных форматах, каждый из которых имеет свои особенности.
В дополнение мы разработали специализированные инструменты для обработки DWG-файлов, 2D-документации и LAS-файлов — облаков точек. 3D-модели, будь то в форматах Autodesk, IFC или нашем S3D, обрабатывались для обеспечения совместимости с нашей платформой. Этот этап стандартизации был критически важен, так как позволил привести все данные к «общему знаменателю», упрощая последующий анализ.
Основой проекта стал модуль сравнения, который анализировал отклонения между стандартизированными данными. Этот модуль был разработан для обработки трех различных сценариев, каждый из которых решал определенные задачи сравнения:
Сценарий 1: Анализ отклонений в конкретных точках
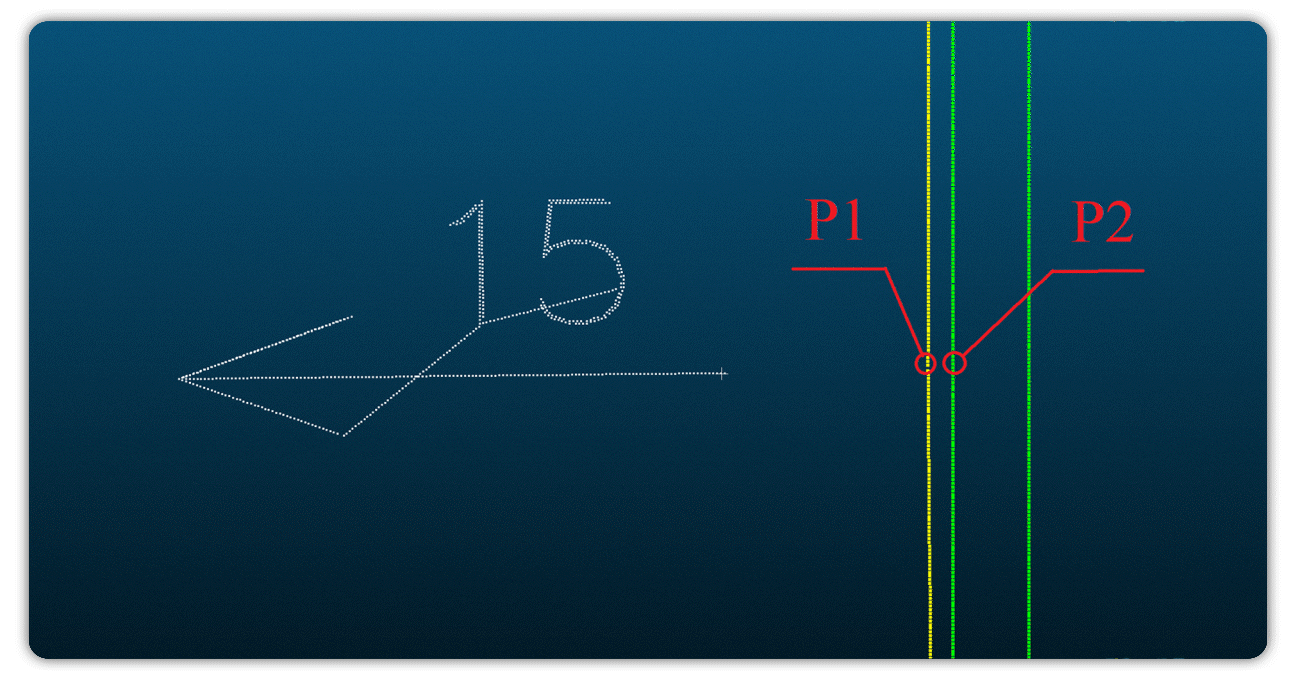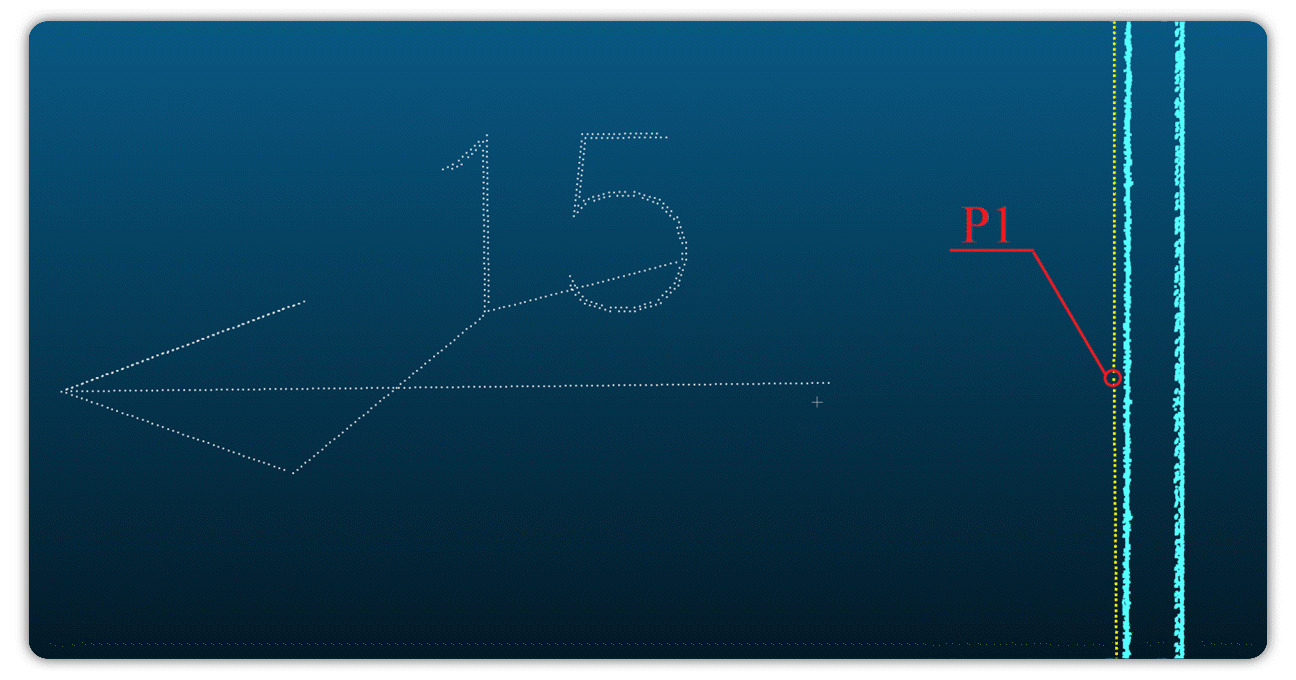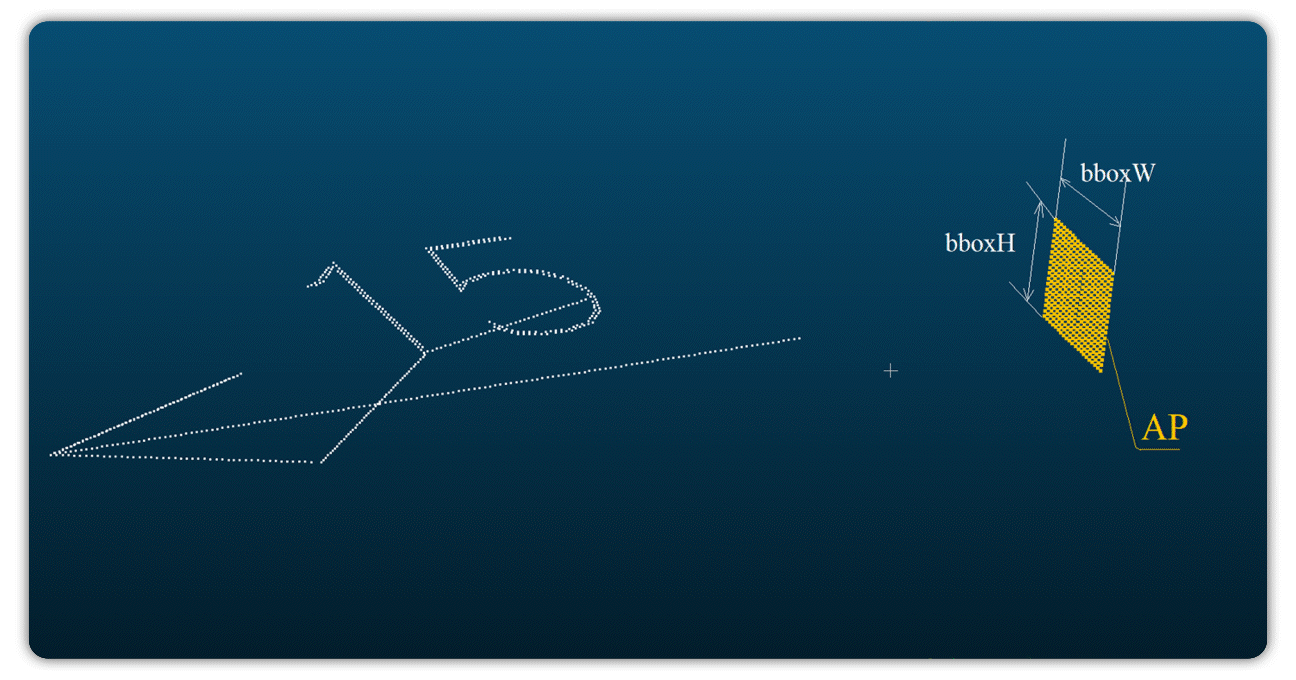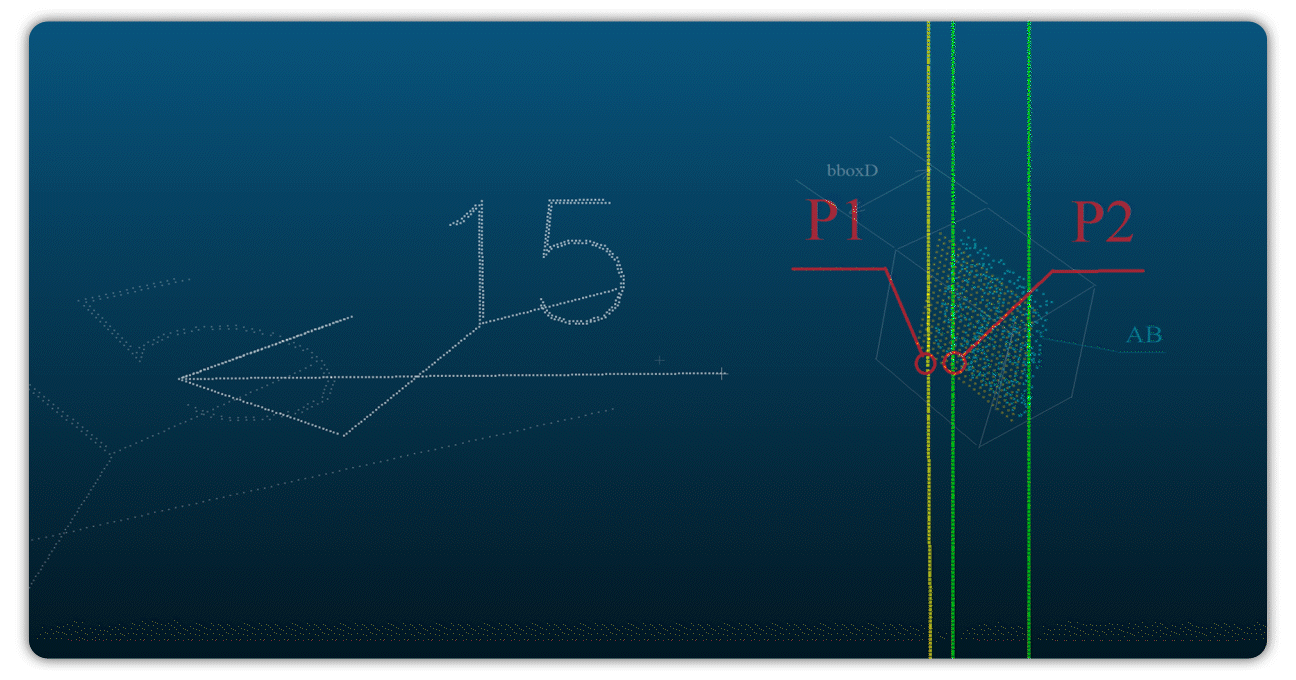
В первом сценарии мы сосредоточились на измерении отклонений в заданных точках, определенных исполнительной документацией. На рисунке 1 рассмотрим ровную стену в складском помещении, спроектированную как идеально прямую в проектной документации (белый контур в 2D-чертеже).
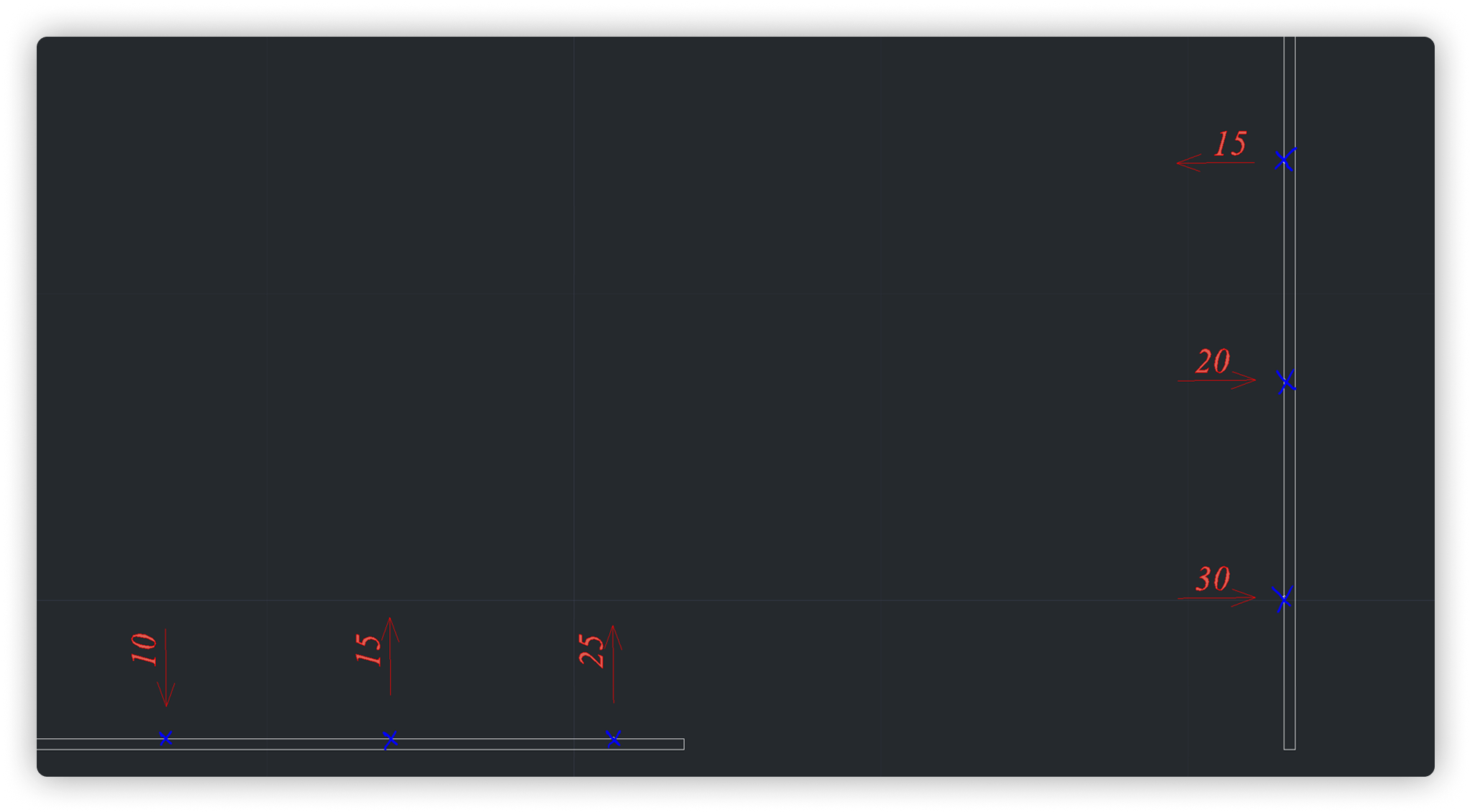
Исполнительные измерения на объекте показали отклонения: например, 20 мм в одной точке, 30 мм в другой и 15 мм в противоположную сторону. Наш алгоритм построил красный контур, отражающий фактическую геометрию стены на основе измерений исполнительной документации, и сравнил его с проектным контуром, вычислив точные отклонения.
Сложность возрастала при сравнении 2D-контуров с облаками точек. В отличие от четких 2D-линий облака точек содержат шум из-за ограничений лазерного сканирования. Даже визуально прямая стена может выглядеть как набор разбросанных точек вдоль прямой линии с небольшими отклонениями (рисунок 2).
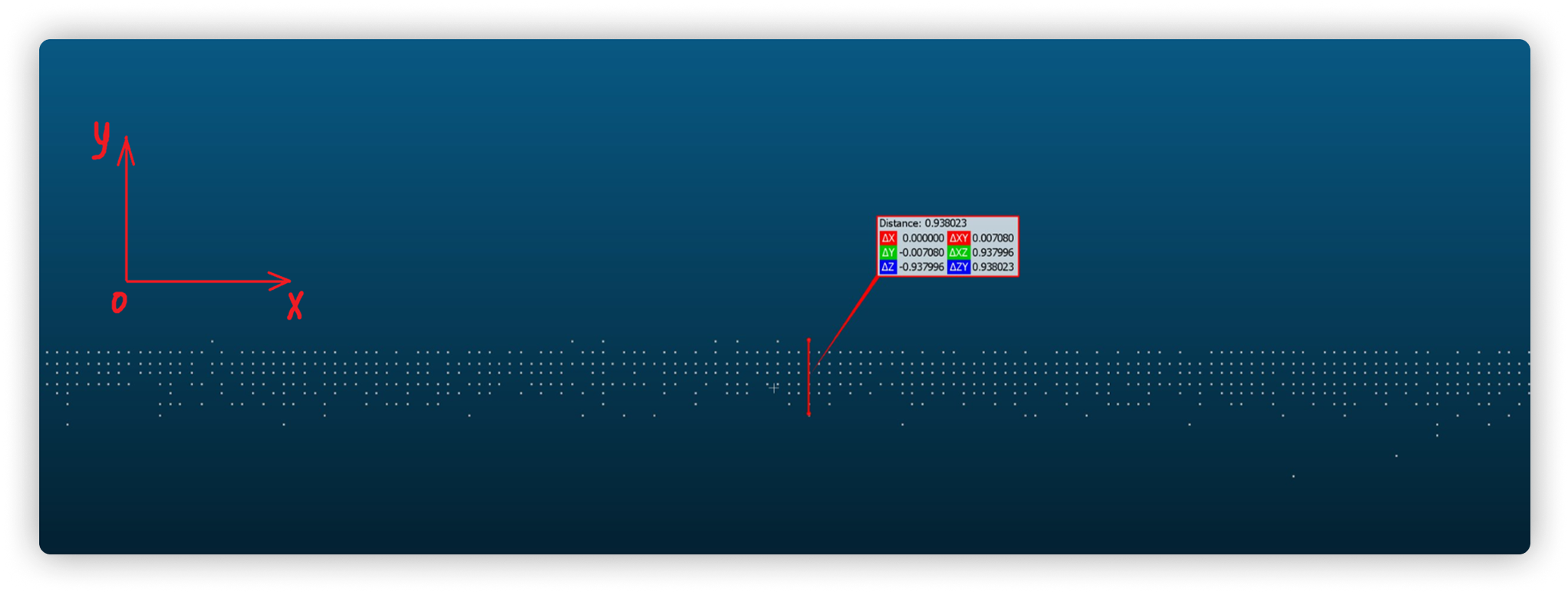
Для решения этой задачи мы разработали метод аппроксимации контура из данных облака точек, фактически воссоздавая реальную геометрию. Этот контур затем сравнивался с проектной документацией, что позволяло точно вычислить отклонения в указанных пользователем точках (рисунок 3).
Сценарий 2: Сегментация и сравнение элементов
Второй сценарий был ориентирован на анализ целых элементов, а не отдельных точек. Например, представьте шесть конструктивных колонн, зафиксированных в облаке точек. Заказчику нужно было понять, построены ли эти элементы согласно проекту, включая их наличие, положение и геометрические размеры. Это потребовало сегментации облака точек на отдельные элементы, каждому из которых присваивался свой цвет для наглядности, например: красный, зеленый, синий (рисунок 4).

Процесс сегментации осложнялся такими явлениями как лазерные тени, когда часть конструкции не попадала в зону сканирования, что приводило к неполным данным. Наш алгоритм успешно выделял и изолировал эти элементы, а затем сравнивал их контуры с данными 2D-проектной документации и 3D-модели.
Построив ограничивающие рамки вокруг каждого сегментированного элемента, мы могли оценить отклонения в положении и размерах, выявляя, например, небольшие повороты или смещения относительно проектного плана.
Сценарий 3: Анализ сложных элементов
Третий сценарий касался более сложных элементов, таких как двутавры (это металлическая или железобетонная балка с поперечным сечением в форме буквы «Н» или латинской «I»). Эти элементы могли присутствовать, отсутствовать или быть построены со смещением в положении, но не в размерах.
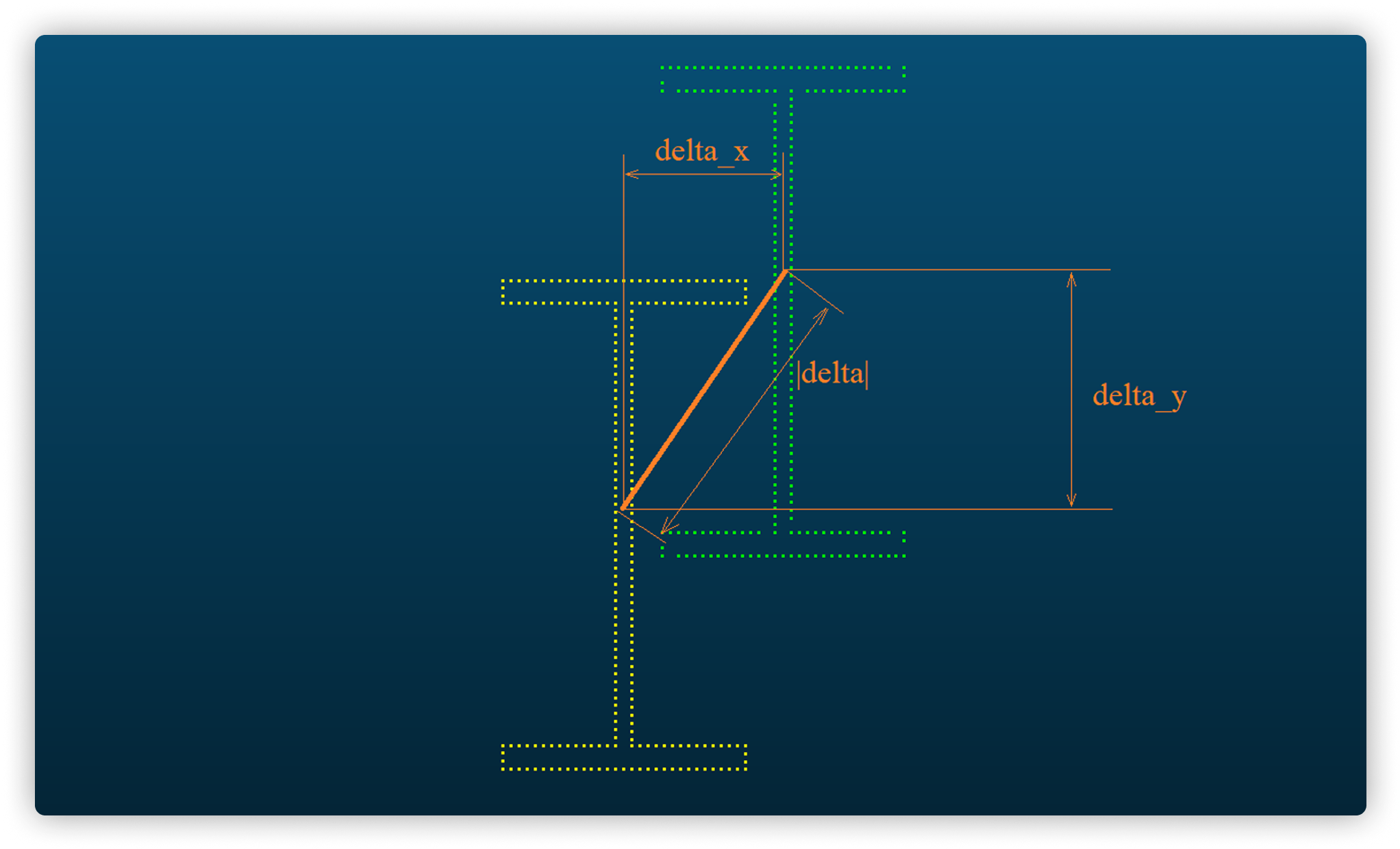
Аналогично первому сценарию, мы извлекали контур из 3D-модели, расширяли его по вертикали для создания объемного сечения и использовали это сечение для «вырезания» соответствующего участка из облака точек (рисунок 5). Это позволяло выравнивать проектный (синий) и фактический (красный) контуры, вычисляя отклонения с высокой точностью.

Сложность заключалась в наличии близлежащих конструкций, таких как стены, которые могли искажать данные облака точек. Тщательно определяя объем сечения, мы минимизировали эти помехи, обеспечивая точное сравнение. Алгоритм автоматически определял наличие элементов и количественно оценивал их позиционные смещения, предоставляя заказчику ценные данные.
Для каждого сценария наша команда создавала визуальные выходные данные, демонстрирующие отклонения между наборами данных (рисунок 7).
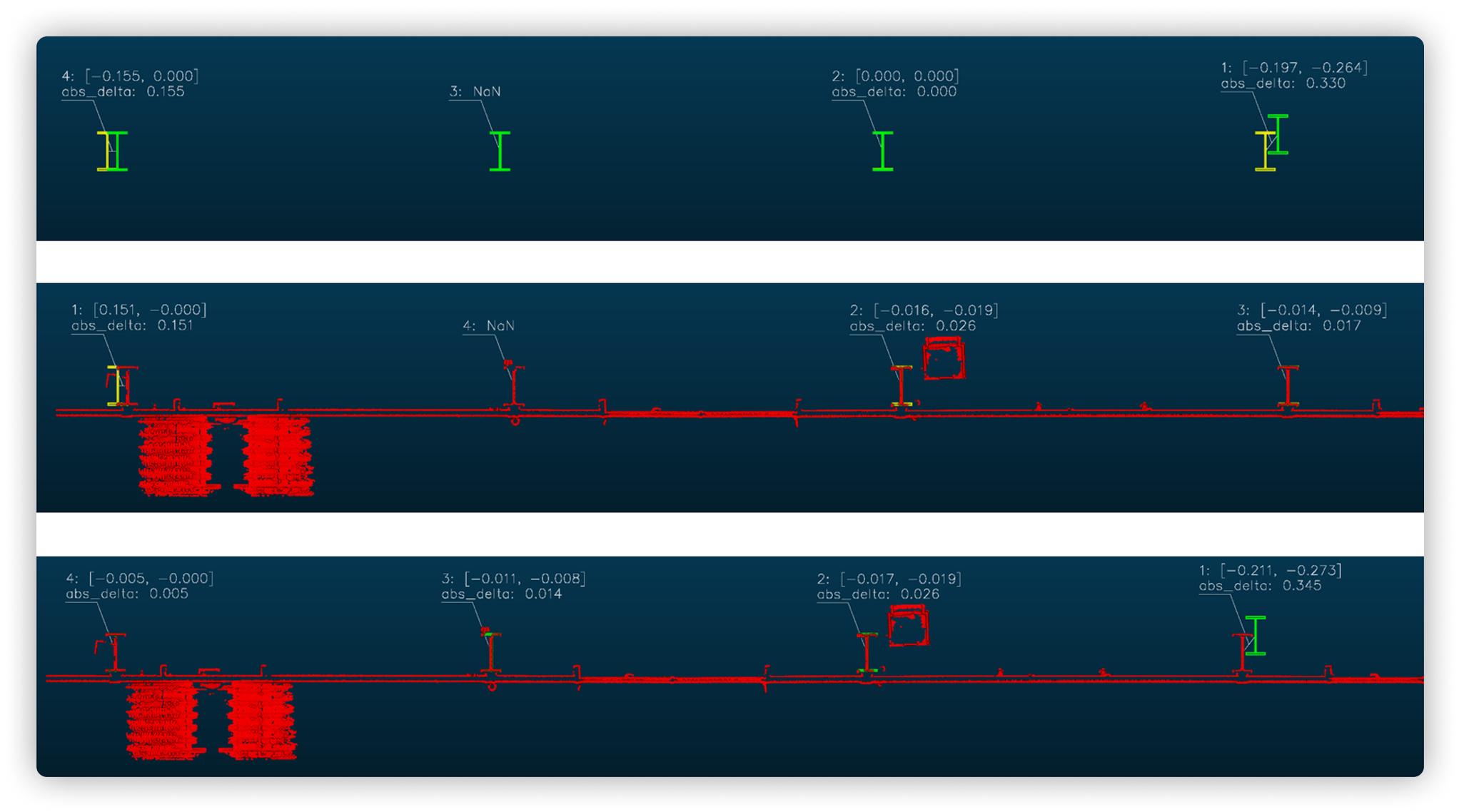
Например, в первом сценарии белый контур (проектная документация) накладывался на красный контур (фактическая конструкция), подчеркивая отклонения в конкретных точках. Во втором сценарии сегментированные элементы обозначались разными цветами, а ограничивающие рамки показывали их реальные размеры. В третьем сценарии отображались выровненные контуры двутавров с аннотациями, указывающими позиционные смещения (например, отклонение на 155 мм).
Проект успешно подтвердил гипотезу: наш автоматизированный инструмент способен сравнивать 3D-модели, облака точек и графическую документацию с точностью более 97%, как указано в технических требованиях.
Во всех трех сценариях алгоритм продемонстрировал способность:
Будьте в курсе всех наших новостей и обновлений, повышайте отраслевую экспертизу вместе с нами

Эффективность и прозрачность на всех этапах жизненного цикла строительства




Участник технопарка «Сколково»
© 2025 Sarex, Все права защищены